I asked Gemini AI about algorithmic recommender systems.
Here’s part of what it said:
An algorithmic recommender system (or “recommendation engine”) is an AI-driven information filtering system designed to predict a user’s preferences and suggest items they are most likely to want, watch, or buy. (https://en.wikipedia.org/wiki/Recommender_system, https://www.ibm.com/think/topics/recommendation-engine)
These algorithms make your digital life easier by sorting through massive amounts of data to surface the most relevant content. They are the backbone of your personalized feeds on apps like Netflix and Amazon. (https://www.esafety.gov.au/industry/tech-trends-and-challenges/recommender-systems-and-algorithms, https://knightcolumbia.org/content/understanding-social-media-recommendation-algorithms, https://en.wikipedia.org/wiki/Recommender_system)
How They Work
Systems typically use a combination of three core machine learning approaches to generate suggestions:
-
Collaborative Filtering: Analyzes the behavior of many users to identify patterns. If “User A” and “User B” have similar tastes, the system recommends items User B likes to User A.
-
Content-Based Filtering: Recommends items with similar characteristics to what you have liked in the past. For example, if you watch several sci-fi action movies, the algorithm will suggest other movies in that specific genre.
-
Hybrid Models: Combines both collaborative and content-based approaches to deliver more accurate and robust predictions. (https://medium.com/recombee-blog/machine-learning-for-recommender-systems-part-1-algorithms-evaluation-and-cold-start-6f696683d0ed, youtube.com/watch?v=iWwQGYkZTAw, https://www.meegle.com/en_us/topics/recommendation-algorithms/recommendation-systems-for-digital-marketing, https://hellopm.co/netflix-content-recommendation-system-product-analytics-case-study/)
Gemini then offered to help me learn how to build a basic recommendation algorithm.
Curious, I told it to do so.
Here’s part of what it showed me:
To build a basic recommendation algorithm, you will typically use a collaborative filtering approach based on cosine similarity, which calculates how closely aligned two users’ preferences are mathematically. (https://pub.aimind.so/recommendation-systems-an-overview-a9ff7d32b043, https://www.uipath.com/community-blog/tutorials/product-sequencing-recommendation-model-with-ai-challenge)
Here is a step-by-step guide to building a fundamental user-based recommendation engine.
1. Structure the User-Item Matrix
First, represent your data as a grid where rows represent users, columns represent items (like movies or products), and the cells contain ratings. Missing values indicate unrated items. (https://www.kaggle.com/code/kanncaa1/recommendation-systems-tutorial, https://www.jillcates.com/pydata-workshop/html/tutorial.html, chrome-extension://efaidnbmnnnibpcajpcglclefindmkaj/https://schools.dvrc.fr/MDD24/workshops/DiversityRS/tutorial.pdf, https://www.linkedin.com/pulse/preparing-data-recommendation-system-vishwajit-sen/, https://medium.com/@murattyldrm7/building-a-recommendation-system-with-lightfm-35394c8d90fb)
2. Calculate Cosine Similarity
To find “similar users,” treat each user’s ratings as a geometric vector. You then calculate the cosine of the angle between two vectors using the formula: (https://medium.com/@Sumeet_Agrawal/various-implementations-of-collaborative-filtering-7429eec37ab9, https://www.proquest.com/openview/4e0f009557289ba072247fe606114d4c/1?pq-origsite=gscholar&cbl=4998668)
• Numerator (\(A \cdot B\)): Multiply corresponding ratings together and sum them up.
• Denominator (\(\|A\| \|B\|\)): Multiply the geometric lengths of both vectors. (https://medium.com/data-science/brief-on-recommender-systems-b86a1068a4dd)
3. Predict the Missing Ratings
Once you know which users are most similar, take a weighted average of their ratings to predict what the target user would score an unviewed item. (https://medium.com/sfu-cspmp/recommendation-systems-user-based-collaborative-filtering-using-n-nearest-neighbors-bf7361dc24e0, https://felixkemeth.medium.com/evaluating-design-choices-of-user-user-collaborative-filtering-across-datasets-f09995547267)
Items with the highest predicted scores are then pushed to the top of the user’s recommendation feed. (https://www.scaler.com/topics/machine-learning/content-based-filtering/)
4. Implement Basic Python Code
You can build a functional prototype using the standard pandas and scikit-learn data science libraries. (https://www.linkedin.com/pulse/supervised-learning-idaly-martinez-lgckc)
✅ Summary of the Build Process
Building a recommendation system relies on mapping user actions to a mathematical matrix, using vector geometry to score behavioral alignment, and calculating a weighted average to forecast future interest. (https://www.spiedigitallibrary.org/conference-proceedings-of-spie/13090/1309034/Personalized-online-learning-recommendation-system-based-on-collaborative-filtering-algorithm/10.1117/12.3026953.full, https://blog.marketingdatascience.ai/an-introduction-to-linear-algebra-the-math-i-slept-through-in-college-that-now-powers-ai-c4831f688496)
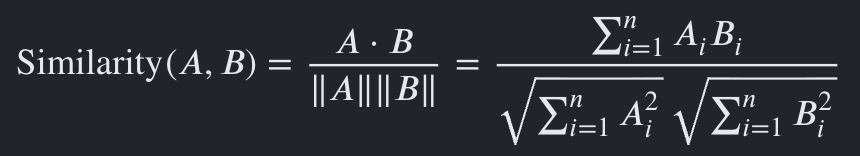
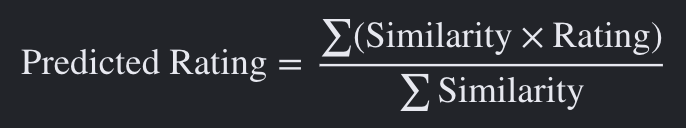
That last reference link regarding linear algebra piqued my interest, so I read a bit more of that source.
Here’s part of what the writer, Joe Domaleski, says:
Linear algebra turns out to be one of the core mathematical foundations of modern artificial intelligence. It clearly sits underneath the neural networks and machine learning systems behind today’s AI tools.
Linear Algebra in Action
You have probably noticed that Netflix seems to know what you want to watch next, or that an ad shows up in your feed at exactly the right moment. That is not a coincidence, and nobody at those companies is manually reviewing your preferences. Something is running underneath all of that, and a big part of it is linear algebra.
Here is the basic idea. Every user gets represented as a long list of numbers. Watch history, time of day, what you skipped, what you finished, how you rated things. Every piece of content gets its own list of numbers too. I will define these lists properly in the next section and call them what they are: vectors. For now, just think of them as a numeric fingerprint.
To figure out whether you will like something, the system measures how similar your fingerprint is to the content’s fingerprint. Do that across millions of users and millions of titles at the same time and you need to organize everything into a grid, which is called a matrix, and run the whole calculation at once. That is matrix multiplication. The entire pipeline, from raw behavior data to the recommendation you see on screen, is a sequence of those operations.
In many modern systems, much of this work happens through math on organized lists of numbers rather than hand-written rules alone.
There are two main flavors of this. User-Based Collaborative Filtering finds people similar to you and recommends what they liked. Item-Based Collaborative Filtering works the other way, recommending things similar to what you have already engaged with.
Enough on algorithmic recommender systems for today. I may revisit this AI skill in a future post. Complicated perhaps, yet intriguing.